ResNet 논문 - Deep Residual Learning for Image Recognition
https://arxiv.org/pdf/1512.03385.pdf
딥러닝에서 네트워크가 깊어질수록 성능은 좋아지지만 학습시키는 과정은 어렵다. 그래서 ResNet은 잔차를 이용한 잔차 학습(residual learning framework)을 이용해 깊은 신경망에서도 학습이 쉽게 이뤄질 수 있다는 것을 보여주고, 방법론을 제시했다.
empirical evidence showing 방법으로
1) residual을 이용한 optimize를 더 쉽게 하는 법,
2) accuracy를 증가시키고 더 깊게 쌓는 법에 초점을 뒀다.
ResNet은 152 layer를 쌓아서 기존의 VGGNet보다 더 좋은 성능을 보였고, 복잡성은 줄였다.
▶Plain Network의 문제점
Plain network는 skip / shortcut connection을 사용하지 않은 일반적인 CNN (AlexNet, VGGNet) 신경망을 의미한다. Plain network의 깊이가 깊어질수록 gradient vanishing 또는 exploding 문제가 발생한다.
신경망이 깊어질수록 더 정확한 예측을 할 수 있을 거라 생각하지만 실제로 논문에 의하면 20-layer plain network가 50-layer plain network보다 더 낮은 train error와 test error를 얻는다. 이를 Degradation problem라 하고 기울기 소실에 의해 발생된다.

degradation problem을 overfitting과 같다 생각하는 사람들도 있을 텐데 엄연히 다르다!!
- Degradation problem은 모든 layer에서 accuracy가 낮다.
(네트워크의 깊이가 깊어질수록 accuracy가 낮음)
- Overfitting은 깊은 layer에서 train의 accuracy는 높지만 낮은 layer에서는 train의 accuracy가 낮다.
degradation problem은 깊은 layer가 쌓일수록 optimize가 복잡해지기 때문에 일어나는 부작용으로 보고 해결하기 위해 Deep residual learning framework이라는 개념을 도입한다.
deep residual learning framework는 쌓인 layer가 그다음 layer에 바로 적합되는 것이 아니라 잔차의 mapping에 적합하도록 만들었다.
▶ Skip / Shortcut Connection in Residual Network
gradient vanishing / exploding을 해결하기 위해 입력 x를 몇 layer 이후의 출력값에 더해주는 skip/shortcut connection을 더해준다.
기존의 바로 다음 layer에 mapping 하는 것이 H(x)라 할 때 논문에서는 비선형적인 layer 적합인 F(x) = H(x) - x를 제시한다. 식을 이항 하면 H(x) = F(x) + x의 형태가 된다.
(여기서 residual mapping이 기존의 mapping보다 더 optimize 하기 쉽다는 것을 가정한다.)
F(x) + x는 Shortcut Connection과 동일한데 이는 하나 또는 이상의 layer를 skip 하게 만들어준다. 따라서 identity mapping으로 shortcut connection이 되게 하면서 skip을 만든다!!

위에 그림에서 x는 input이고 F(x)는 model이다. x가 F(x)라는 일련의 과정을 거치면서 자기 자신(identity)인 x가 더해져 output은 F(x) + x가 된다.
ResNet의 목표는 다음과 같다.
1) plain net보다 residual net이 더 쉽게 최적화되어야 한다.
2) residual net이 더 쉽게 accuracy 높이는 것을 보여줘야 한다.
▶ Identity Mapping by Shortcuts


단순 덧셈으로 인해 복잡한 구조와 연산이 필요 없다는 것이 이 방법의 핵심이기 때문에 이 로테이션을 통해 직관적으로 보여주는데, x의 경우 ReLU 함수를 한 번 통과했고 bias는 생략해서 나타낸다. 이때 x와 F의 차원이 동일해야 하는데 W1, W2 등 Linear projection을 사용해서 같은 차원으로 만들어 준다,
▶ResNet의 구조
논문에서는 VGG net, Plain net, Residual net을 비교한다.

여기서 34-layer plain은 VGG-10가 더 깊어진 구조이고, 34-layer residual network(ResNet)은 plain network에 skip/short connection이 추가된 것이다.
skip/short connection을 추가하기 위해서는 더해지는 값 x와 출력값의 차원이 같아야 하는데 (앞에서 언급) , ResNet에서는 입력 차원이 출력 차원보다 작을 때 사용하는 3종류의 skip/shortcut connection이 있다.
(A) shortcut은 증가하는 차원에 대해 추가적으로 zero-padding을 적용해 identity mapping을 수행 (추가적인 파라미터 X)
(B) 차원이 증가할 때만 projection shortcut을 사용하고 다른 shortcut은 identity이다. (추가적인 파라미터 O)
(C) 모든 shortcut이 projection (B보다 많은 파라미터 필요)
이 논문에서는 모델의 연산량이 증가하기 때문에 C 방법은 사용하지 않았다.
Bottleneck은 A 방법을 사용한다.
▶Bottleneck
Bottleneck은 신경망의 복잡도를 감소하기 위해 사용한다.

오른쪽 그림을 보면 1x1 Conv layers가 신경망 시작과 끝에 추가되었다. 이 기법은 NIN(Network In Network)과 GoogLeNet에서 제안되었다. 1x1 Conv는 신경망의 성능을 감소시키지 않고, 파라미터 수를 감소시킨다!!
따라서 bottleneck design으로 연산량을 감소시켜 34-layer가 50-layer ResNet이 되고, bottleneck design을 지닌 더 깊은 신경망 ResNet-101과 ResNNet-152이 생겼다.
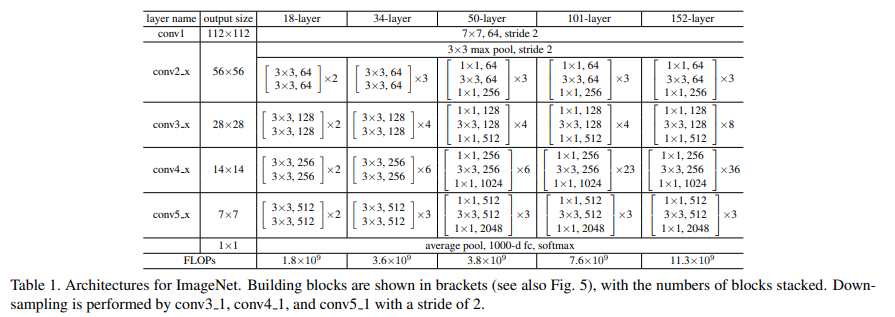
ResNet-152가 VGG-16보다 더 적은 연산량을 갖고 있다.
▶Plain network VS ResNet


- Plain network에서 gradient vanishing 문제 때문에 18-layers의 성능이 34-layers보다 더 뛰어나다.
- ResNet에서는 gradient vanishing 문제가 skip connection에 의해 해결되어 34-layers의 성능이 18-layers 보다 더 뛰어나다.
▶ResNet 구현
처음에는 bottleneck 구조가 이해가 잘 안 됐었는데,, 코드를 쳐보면서 이해할 수 있게 되었다! 시간상 모델을 이용해 학습을 시키고 할 수는 없지만 간단하게라고 모델의 구조를 알아보고 지나가야겠다!!
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from torch import optim
from torch.optim.lr_scheduler import StepLR# Standard
class Standard(nn.Module):
def __init__(self, in_dim=256, mid_dim=64, out_dim=64):
super(BuildingBlock, self).__init__()
self.building_box = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=mid_dim,
kernel_size=3, padding=1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels=mid_dim, out_channels=out_dim,
kernel_size=3, padding=1, bias=False),
nn.ReLU()
)
self.relu = nn.ReLU()
def forward(self, x):
fx = self.building_block(x) # F(x)
out = fx + x # F(x) + x
out = self.relu(out)
return out
# Bottleneck
class Bottleneck(nn.Module):
def __init__(self, in_dim=256, mid_dim=64, out_dim=256):
super(Bottleneck, self).__init__()
self.Bottleneck = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=mid_dim,
kernel_size=1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels=mid_dim, out_channels=mid_dim,
kernel_size=3, padding=1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels=mid_dim, out_channels=out_dim,
kernel_size=1, bias=False),
nn.ReLU()
)
self.relu = nn.ReLU()
def forward(self, x):
fx = self.Bottleneck(x) # F(x)
out = fx + x
out = self.relu(out)
return out
reference
https://deep-learning-study.tistory.com/473
https://coding-yoon.tistory.com/116
'PAPER REVIEW > Classification' 카테고리의 다른 글
| [논문 리뷰] 6. SENet의 구조 & 구현 (0) | 2022.07.12 |
|---|---|
| [논문 리뷰] 4. GoogLeNet의 구조 (0) | 2022.07.10 |
| [논문 리뷰] 3. VGGNet의 구조 & 구현 (0) | 2022.07.07 |
| [논문 리뷰] 2. AlexNet의 구조 & 구현 (0) | 2022.07.07 |
| [논문 리뷰] 1. LeNet-5의 구조 & 구현 (0) | 2022.07.06 |