SENet은 채널간의 상호작용에 집중하여 성능을 끌어올린 모델이다. 채널간의 상호작용은 가중치로 생각할 수 있는데 가중치가 클경우 중요한 특징을 지니고 있다는 것을 의미한다. feature map의 각 채널마다 가중치를 부여해 feature map의 각 채널에 곱해준다. 따라서 SENet은 채널 간의 가중치를 계산해 성능을 끌어올린 모델이라 생각할 수 있다.
▶ SE Block
SE Block은 Squeeze (압축) + Excitation (재조정)을 하는 것으로 CNN 기반 모델에 부착하여 사용한다. residual 모델(ResNet) 또는 inception 모델(GoogLeNet) 과 함께 사용하거나 또 VGGnet에도 부착하여 사용할 수 있기 때문에 SE Block 은 유연성을 지니고 있다고 볼 수 있다.
SE Block은 feature를 추출할때 클래스와 관련이 있다.
Low level에서는 클래스와 상관없이 중요한 feature 추출
- High level에서는 클래스와 관련있는 feature 추출
SE Block은 Squeeze(압축)과 Excitation(재조정) 두 과정으로 구성된다.
1) Squeeze (압축)
각 채널을 1차원으로 만드는 역할을 한다.
Squeeze는 conv 연산을 통해 생성된 feature map을 입력받는다. HxWxC 크기의 feature map을 global average pooling 연산을 통해 1x1xC로 압축한다. feature map의 한 채널에 해당하는 픽셀 값을 모두 다 더한 다음에 HxW로 나눠 1x1x1로 압축한다. feature map은 C개의 채널을 갖고 있으므로 다 연결하면 1x1xC가 된다. 생성된 1x1xC 벡터는 Excitation으로 전달된다.
2) Excitation (재조정)
Squeeze에서 생성된 1x1xC 벡터를 정규화해서 가중치를 부여하는 역할을 한다. FC → ReLU → FC → Sigmoid로 구성되어 있다. FC에 1x1xC 벡터가 입력되면 C채널을 C/r로 축소한다. 이때 r은 하이퍼파라미터이다. C/r개의 채널로 축소된 1x1xC/r가 된 벡터는 ReLU로 전달되고, FC를 통과해 다시 C로 되돌아 간다. 채널이 C → C/r → C로 변화하는데 이는 연산량의 제한과 일반화 효과때문에 bottleneck구조를 선택했다고 한다. sigmoid를 거쳐서 [0~1) 범위의 값을 지니게 되고, feature map과 곱해져 feature map의 채널에 가중치를 가한다.
▶ SENet의 구조
앞에서 SE Block은 유연성을 지니고 있다 했는데 여기서는 ResNet-50에 부착되어 사용됐다.
여러 모델에 SE Block을 부착했을 때와 부착하지 않았을 때의 성능을 비교해보고자 한다.
확실히 SE Block을 부착했을 때 top-1 와 top-5 error가 줄어든 것을 확인할 수 있다.
▶ SENet 구현
직접 모델을 사용하고 데이터셋을 이용해 학습시키기에는 안 배운 내용들이 많아서 SE Block 정도만 구현해보고자 한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from torch import optim
from torch.optim.lr_scheduler import StepLR
# SEBlock
class SEBlock(nn.Module):
def __init__(self, in_channels, r=16):
super.__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1,1))
self.excitation = nn.Sequential(
nn.Linear(in_channels, in_channels//r),
nn.ReLU(),
nn.Linear(in_channels//r, in_channels),
nn.Sigmoid()
)
def forward(self, x):
x = self.squeeze(x)
x = x.view(x.size(0), -1)
x = self.excitation(x)
x = x.view(x.size(0), x.size(1), 1, 1)
return x
딥러닝에서 네트워크가 깊어질수록 성능은 좋아지지만 학습시키는 과정은 어렵다. 그래서 ResNet은 잔차를 이용한 잔차 학습(residual learning framework)을 이용해 깊은 신경망에서도 학습이 쉽게 이뤄질 수 있다는 것을 보여주고, 방법론을 제시했다.
empirical evidence showing 방법으로
1) residual을 이용한 optimize를 더 쉽게 하는 법,
2) accuracy를 증가시키고 더 깊게 쌓는 법에 초점을 뒀다.
ResNet은 152 layer를 쌓아서 기존의 VGGNet보다 더 좋은 성능을 보였고, 복잡성은 줄였다.
▶Plain Network의 문제점
Plain network는 skip / shortcut connection을 사용하지 않은 일반적인 CNN (AlexNet, VGGNet) 신경망을 의미한다. Plain network의 깊이가 깊어질수록 gradient vanishing 또는 exploding 문제가 발생한다.
신경망이 깊어질수록 더 정확한 예측을 할 수 있을 거라 생각하지만 실제로 논문에 의하면 20-layer plain network가 50-layer plain network보다 더 낮은 train error와 test error를 얻는다. 이를 Degradation problem라 하고 기울기 소실에 의해 발생된다.
degradation problem을 overfitting과 같다 생각하는 사람들도 있을 텐데 엄연히 다르다!!
- Degradation problem은 모든 layer에서 accuracy가 낮다.
(네트워크의 깊이가 깊어질수록 accuracy가 낮음)
- Overfitting은 깊은 layer에서 train의 accuracy는 높지만 낮은 layer에서는 train의 accuracy가 낮다.
degradation problem은 깊은 layer가 쌓일수록 optimize가 복잡해지기 때문에 일어나는 부작용으로 보고 해결하기 위해 Deep residual learning framework이라는 개념을 도입한다.
deep residual learning framework는 쌓인 layer가 그다음 layer에 바로 적합되는 것이 아니라 잔차의 mapping에 적합하도록 만들었다.
▶ Skip / Shortcut Connection in Residual Network
gradient vanishing / exploding을 해결하기 위해 입력 x를 몇 layer 이후의 출력값에 더해주는 skip/shortcut connection을 더해준다.
기존의 바로 다음 layer에 mapping 하는 것이 H(x)라 할 때 논문에서는 비선형적인 layer 적합인 F(x) = H(x) - x를 제시한다. 식을 이항 하면 H(x) = F(x) + x의 형태가 된다.
(여기서 residual mapping이 기존의 mapping보다 더 optimize 하기 쉽다는 것을 가정한다.)
F(x) + x는Shortcut Connection과 동일한데 이는 하나 또는 이상의 layer를 skip 하게 만들어준다. 따라서 identity mapping으로 shortcut connection이 되게 하면서 skip을 만든다!!
위에 그림에서 x는 input이고 F(x)는 model이다. x가 F(x)라는 일련의 과정을 거치면서 자기 자신(identity)인 x가 더해져 output은 F(x) + x가 된다.
ResNet의 목표는 다음과 같다.
1) plain net보다 residual net이 더 쉽게 최적화되어야 한다.
2) residual net이 더 쉽게 accuracy 높이는 것을 보여줘야 한다.
▶ Identity Mapping by Shortcuts
단순 덧셈으로 인해 복잡한 구조와 연산이 필요 없다는 것이 이 방법의 핵심이기 때문에 이 로테이션을 통해 직관적으로 보여주는데, x의 경우 ReLU 함수를 한 번 통과했고 bias는 생략해서 나타낸다. 이때 x와 F의 차원이 동일해야 하는데 W1, W2 등 Linear projection을 사용해서 같은 차원으로 만들어 준다,
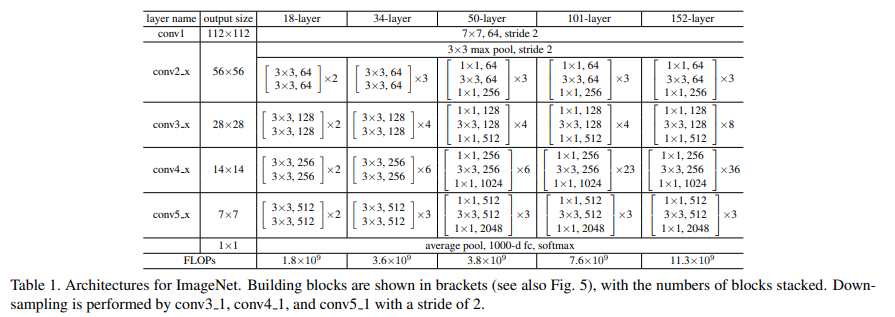
▶ResNet의 구조
논문에서는 VGG net, Plain net, Residual net을 비교한다.
여기서 34-layer plain은 VGG-10가 더 깊어진 구조이고, 34-layer residual network(ResNet)은 plain network에 skip/short connection이 추가된 것이다.
skip/short connection을 추가하기 위해서는 더해지는 값 x와 출력값의 차원이 같아야 하는데 (앞에서 언급) , ResNet에서는 입력 차원이 출력 차원보다 작을 때 사용하는 3종류의 skip/shortcut connection이 있다.
(A) shortcut은 증가하는 차원에 대해 추가적으로 zero-padding을 적용해 identity mapping을 수행 (추가적인 파라미터 X)
(B) 차원이 증가할 때만 projection shortcut을 사용하고 다른 shortcut은 identity이다. (추가적인 파라미터 O)
(C) 모든 shortcut이 projection (B보다 많은 파라미터 필요)
이 논문에서는 모델의 연산량이 증가하기 때문에 C 방법은 사용하지 않았다.
Bottleneck은 A 방법을 사용한다.
▶Bottleneck
Bottleneck은 신경망의 복잡도를 감소하기 위해 사용한다.
오른쪽 그림을 보면 1x1 Conv layers가 신경망 시작과 끝에 추가되었다. 이 기법은 NIN(Network In Network)과 GoogLeNet에서 제안되었다. 1x1 Conv는 신경망의 성능을 감소시키지 않고, 파라미터 수를 감소시킨다!!
따라서 bottleneck design으로 연산량을 감소시켜 34-layer가 50-layer ResNet이 되고, bottleneck design을 지닌 더 깊은 신경망 ResNet-101과 ResNNet-152이 생겼다.
ResNet-152가 VGG-16보다 더 적은 연산량을 갖고 있다.
▶Plain network VS ResNet
- Plain network에서 gradient vanishing 문제 때문에 18-layers의 성능이 34-layers보다 더 뛰어나다.
- ResNet에서는 gradient vanishing 문제가 skip connection에 의해 해결되어 34-layers의 성능이 18-layers 보다 더 뛰어나다.
▶ResNet 구현
처음에는 bottleneck 구조가 이해가 잘 안 됐었는데,, 코드를 쳐보면서 이해할 수 있게 되었다! 시간상 모델을 이용해 학습을 시키고 할 수는 없지만 간단하게라고 모델의 구조를 알아보고 지나가야겠다!!
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from torch import optim
from torch.optim.lr_scheduler import StepLR
# Standard
class Standard(nn.Module):
def __init__(self, in_dim=256, mid_dim=64, out_dim=64):
super(BuildingBlock, self).__init__()
self.building_box = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=mid_dim,
kernel_size=3, padding=1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels=mid_dim, out_channels=out_dim,
kernel_size=3, padding=1, bias=False),
nn.ReLU()
)
self.relu = nn.ReLU()
def forward(self, x):
fx = self.building_block(x) # F(x)
out = fx + x # F(x) + x
out = self.relu(out)
return out
# Bottleneck
class Bottleneck(nn.Module):
def __init__(self, in_dim=256, mid_dim=64, out_dim=256):
super(Bottleneck, self).__init__()
self.Bottleneck = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=mid_dim,
kernel_size=1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels=mid_dim, out_channels=mid_dim,
kernel_size=3, padding=1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels=mid_dim, out_channels=out_dim,
kernel_size=1, bias=False),
nn.ReLU()
)
self.relu = nn.ReLU()
def forward(self, x):
fx = self.Bottleneck(x) # F(x)
out = fx + x
out = self.relu(out)
return out
GoogLeNet은 VGGNet을 제치고 우승한 모델이다. 사실 교수님께서 공부하라고 주신 논문 리스트에는 없었지만 나는 공부를 하는 거니까...! 가볍게 보고 지나가려 한다!! GoogLeNet의 핵심인 Inception block과 추가적인 기법에 대해 공부해보자!!
GoogLeNet은 22층을 가진 DNN(Deep Neural Netwok)이다. neral network는 깊이와 넓이가 증가할수록 높은 정확도를 얻을 수 있지만 두 가지의 단점을 가진다.
1) 기하급수적으로 parameter 증가
: parameter 수가 많아지면 overfitting이 발생되기 쉽고, bottleeck을 만들어낸다.
2) 메모리 사용량 증가
: 계산 용량은 유한하므로 계산 자원의 효율적인 분포가 필요하다.
논문에 의하면 GoogLeNet에서 주목할 점은 전력과 메모리 사용을 효율적으로 설계하여 모바일이나 임베디드 환경에 적용시킬 수 있게 했다는 것이다. 실제로 GoogLeNet은 AlexNet보다 정확도는 뛰어나지만 parameter 수가 12배 적다고 한다!!
▶ GoogLeNet 의 철학
위에서 언급한 두 가지 문제점을 해결하기 위해 GoogLeNet은 sparse 한 data구조에 집중한다. 이를 위해 NIN(Network IN Network) 논문을 인용한다.
NIN은 높은 상관관계에 있는 neuron들을 군집화시키고 마지막 계층에서 활성화 함수들의 상관관계를 분석함으로써 최적의 network topology를 구축할 수 있다고 말한다. 간단히 말하면 컨볼루션을 수행할 때, 수행 후 feature map을 얻는데 multilayer perceptron 네트워크를 컨볼루션 시 추가로 적용하여 feature map을 만든다.
이를 통해 fully connected layer와 convolutional layer를 dense 구조에서 sparse 구조로 바뀔 수 있다고 한다.
sparse 구조로 바꿔서 효율적인 데이터 분포를 만들어내 더 깊고 넓은 네트워크를 만들어 정확도를 높일 수 있지만 불균일한 sparse 데이터에서 수치계산은 매우 비효율적이다는 단점을 가지고 있다.
▶ Inception Module
GoogLeNet의 핵심인 Inception module이다. inception module의 주요 아이디어는 컨볼루션 네트워크에서 sparse구조를 손쉽게 dense 요소들로 근사화하고 다룰 수 있는 방법을 찾는 것에 근거한다.
inception module에서 feature map을 효과적으로 추출하기 위해 filter size를 1x1, 3x3, 5x5으로 제한했다. incpetion은 이러한 layer들이 모여 next stage의 입력으로 들어간다. cnn의 성공에 있어 pooling이 필수적이기 때문에 pooling연산에 padding을 추가해준다. ( 각각 matrix의 height, width가 같아야 함! )
이러한 inception 모듈은 점점 위로 (output 쪽으로) 쌓이게 된다. 이때 고차원의 특징들은 output에 가까워질수록 잘 포착되기 때문에 spatial concentration은 감소한다. 따라서 3x3와 5x5 conv layer의 비율을 output에 가까워질수록 늘려야 하는데 이때 연산량이 증가하게 된다. 따라서 기존의 방식(naive version) 대신 새로운 버전의 inception모듈이 만들어졌다.
새로운 버전의 incption 모듈은 1x1 conv를 제외하고 각각의 conv layer 앞에와 pooling layer 뒤에 1x1 conv를 추가해주었다. (max pooling에 stride=2로 사용)
논문에 의하면 1x1 Conv는 두 가지의 목적으로 사용됐다.
1) computational bottleneck을 해결하기 위해 dimension reduction으로 작용했다.
2) 성능의 심각한 저하 없이 network의 깊이와 너비를 증가시킬 수 있게 되었다.
▶ GoogLeNet 구조
inception module을 통해 다양한 특징을 추출하고 파라미터 연산량을 개선한 GoogLeNet의 구조는 다음과 같다.
각 컨볼루션에는 ReLU 함수가 적용됐다. 또한 optimizer는 0.9 모멘텀을 지닌 SGD를 이용한다. 매 8 에폭마다 4%의 학습률을 낮춰줬다고 한다.
위 표는 GoogLeNet의 구성을 나타낸 것으로 모델의 깊이가 매우 깊어진 것을 확인할 수 있다. 실험에서 앙상블 기법을 적용했는데 성능이 살짝 향상되었다.
모델의 깊이가 깊어지면 gradient vanishing 문제가 발생할 수 있기 때문에 역전파시키는 것이 중요한 문제가 된다. 따라서 모든 layer에 효과적인 방법으로 gradient를 뒤로 전달하기 위해 auxiliary classifier를 중간 layer에 추가해줬다. auxiliary classifier 덕분에 기울기의 신호가 증가되고, 추가적인 regularization 효과를 얻을 수 있다.
GoogLeNet에서 image sampling method는 매우 자주 바뀌었다고 한다. 이러한 변경이 dropout, learning rate, hyperparameter의 변경과 같이 이루어지기 때문에 효율적인 image sampling method를 설명하기 어렵다고 한다.
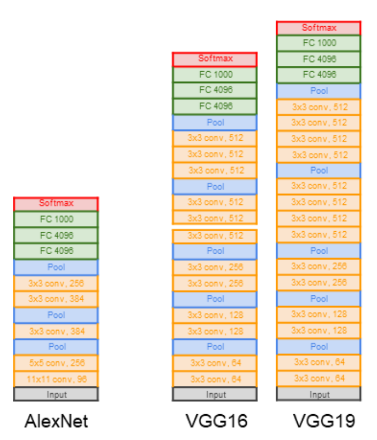
VGGNet은 ILSVRC 대회에서 GoogLeNet 보다 이미지 분류 성능은 낮았지만, 네트워크의 깊이가 모델이 좋은 성능을 보이는데 중요한 역할을 한다는 것을 보여준다. AlexNet과 비교해봤을 때 네트워크가 깊어지고 더 작은 필터를 사용했다는 것을 확인할 수 있다!!
▶ VGGNet 구조
VGGNet은 AlexNet의 8-layers 모델보다 깊이가 2배 이상 깊어졌고 오차율도 16.4%→ 7.3%로 절반이나 줄었다. VGGNet이 16~19 layers에 달하는 깊은 신경망을 학습할 수 있었던 것은 모든 합성곱 레이어에서 3x3 필터를 사용했기 때문이라 할 수 있다.
[VGG-16 구성]
- 13 Conv layers + 3 FC layers
- 3x3 conv filters
- stride = 1, padding = 1
- 2x2 max pooling (stride = 2)
- ReLU
깊이를 서로 달리 한 모델 A~E의 배치가 있다. 11~19 layer 범위의 깊이로 실험이 진행되었고, channels는 각 max-pooling layer 이후에 2배씩 증가한다.
아래는 각 배치의 parameter 수가 나와있다.
입력 사이즈는 224x224 크기의 컬러 영상을 사용하며, 하나 or 복수의 conv layer와 max-pooling layer가 반복되는 구조이고 최종단에 fc layer가 구성되어 있다.
전처리 단계에서 AlexNet과 비교해보면
학습 데이터셋의 전체 학습 데이터셋 전체의 채널 평균값을 입력 영상의 각 pixel마다 빼주고 입력을 zero-centered 되게 한다. 그리고 기존의 7x7 사이즈보다 작은 크기의 필터를 사용함으로써 파라미터 수를 줄일 수 있었다. 하지만 그럼에도 불구하고 FC layer로 인해 상당한 파라미터를 가지게 된다. 이 부분이 VGGNet의 단점이라 할 수 있다. 가장 간단한 A 구조에서도 파라미터의 수가 133백만 개이다..!
(참고로 GoogLeNet은 Fully-connected layer가 없다!!)
[3x3 filter 사용]
VGGNet 이전 모델들은 비교적 큰 receptive field를 갖는 11x11 filter 또는 7x7 filter를 포함했다. 하지만 VGGNet은 오직 3x3 크기의 작은 필터만 사용했고, 그럼에도 불구하고 이미지 분류 정확도를 개선시켰다.
stride = 1 일 때, 3번의 3x3 conv 필터링을 반복한 feature map은 한 pixel 이 원본 이미지의 7x7 receptive field의 효과를 볼 수 있다.
그렇다면 왜 VGGNet은 3x3 filter를 이용했을까?
1) 결정 함수의 비선형성 증가
: 각 컨볼루션 연산은 ReLU 함수를 포함한다. 따라서 1-layer 7x7 filter의 경우 한 번의 비선형 함수가 적용되지만 3-layer 3x3 filter는 세 번의 비선형 함수가 적용된다. layer가 증가함에 따라 비선형성이 증가하고, 모델의 특징 식별성이 증가하는 것을 알 수 있다. ( layer 증가 → 비선형성 증가 → 모델의 특징 식별성 증가 )
2) 학습 파라미터 수 감소
1-layer 7x7 filter : 1 * 7 * 7 = 49
3-layer 3x3 filter : 3 * 3 * 3 = 27
3x3 filter를 사용했을 때 파라미터 수가 크게 감소하는 것을 확인할 수 있다.
▶ Classification Framework
VGGNet은 3x3 conv 라는 단순한 구조로부터 성능을 끌어내기 위해 training과 test에 많은 공을 들였다.
신경망 가중치의 초기화는 학습 속도 및 안정성에 큰 영향을 줄 수 있기 때문에 어떤 방법을 이용할 것인지 정하는 것은 중요한 문제이다. 논문에서 사용한 방법은 다음과 같다.
- 가장 얇은 구조인 11-layer (A 구조) 를 학습시킨 후 학습된 1번째, 4번째 conv layer와 3개의 fc layer의 가중치를 이용해 다른 깊은 모델을 학습시켰다. 미리 가중치가 설정되어 수렴하기까지의 적은 epoch이 필요했던 것이다. 그리고 가중치 초기화 값은 평균 0, 분산 0.01인 정규분포에서 무작위로 추출했다.
(논문을 제출하고 나서 무작위 초기화 절차를 이용하여 사전 훈련 없이 가중치를 초기화하는 것이 가능하다는 것을 알아냈다고 한다.)
3) Data Agumentation
- crop된 이미지를 무작위로 수평 뒤집기
- 무작위로 RGB 값 변경하기
- image rescaling >> 모델 학습 시 입력 이미지의 크기를 모두 224x224로 고정
이 부분을 AlexNet과 GoogLeNet과 비교를 해보면,
AlexNet은 모든 학습 이미지를 256x256 크기로 만든 후 거기서 무작위로 224x224 크기의 이미지를 취하는 방식으로 학습 데이터 크기를 2048배로 늘리고, RGB 컬러를 주성분 분석을 사용해 RGB 데이터를 조작하는 방식을 사용했다. 하지만 AlexNet에서는 모든 이미지가 256x256 크기의 single scale 이었다.
GoogLeNet은 영상의 가로/세로 비를 [3/4, 4/3]의 범위를 유지하면서 원영상의 8~100%까지 포함할 수 있도록 다양한 크기의 parch를 학습에 사용했다. 또한 photometric distortion을 통해 학습 데이터의 양을 증가시켰다.
VGGNet에서는 single scale training과 multi scaling training을 지원한다.
single scale에서는 AlexNet과 마찬가지로 S(training scale) = 256, S = 384 두개의 scale 고정을 지원한다.
multi scale에서는 S를 Smin = 256 ~ Smax = 512 범위에서 무작위로 선택할 수 있게 했다. 따라서 256~512 범위에서 무작위로 scale을 정할 수 있기 때문에 다양한 크기에 대한 대응이 가능해 정확도가 올라간다.
multi scale 학습은 S가 384 일때 미리 학습을 시킨 후 S를 무작위로 선택해 가며 fine tuning을 하는데 이 방법을 scale jittering이라고 한다.
이처럼 학습 데이터를 다양한 크기로 변환하고 그 중 일부분을 샘플링해 사용함으로써 몇가지 효과를 얻을 수 있다.
- 한정적인 데이터의 수를 늘릴 수 있다. (Data agumentation)
- 하나의 object에 대한 다양한 측면을 학습 할 때 반영시킬 수 있다.
(변환된 이미지가 작을수록 개체의 전체적인 측면을 학습할 수 있고, 변환된 임지가 클수록 개체의 특정한 부분을 학습에 반영할 수 있다.)
실제로 실험 결과에 따르면 다양한 스케일로 변환한 이미지에서 샘플링하여 학습 데이터로 사용한 경우가 단일 스케일 이미지에서 샘플링한 경우보다 분류 정확도가 좋았다고 한다!!
[Testing]
training 완료된 모델을 테스팅할 때는 신경망의 마지막 3개의 fully-connected layers를 convolutional layers로 변환하여 사용했다.
첫 번째 FC layer는 7x7 Conv로, 뒤에 두개의 FC layer는 1x1 Conv로 변환했다. 이런식으로 변환된 신경망을 Fully-Convolutional Networks 라고 한다.
신경망이 Conv layer로만 구성될 경우 입력 이미지의 크기 제약이 없어진다. 따라서 하나의 입력 이미지를 다양한 스케일로 사용한 결과들을 앙상블하여 이미지 분류 정확도를 개선하는 것도 가능해진다.
▶ Classification Experiments
[ Single scale evaluation]
- A vs A-LRN
AkexNet에서 사용했던 LRN(Local Response Normalization) 효과 X
- A ~ E
깊이가 깊어질수록 error 감소
-scale [256~512]
다양한 스케일로 resize한 것이 고정된 스케일보다 성능이 더 좋음
[ Multi scale evaluation]
-Q(test)의 변화
Q값을 [S-32, S, S+32] 로 변화시키면서 테스트를 했다. 학습의 스케일과 테스트의 스케일이 많이 차이가 나는 경우 오히려 결과가 더 좋지 못해 32만큼 차이가 나게 하여 테스트를 진행했다.
학습에 scale jittering을 적용한 경우 출력의 크기는 [256, 384, 512]로 테스트 영상의 크기를 정했으며, scale jittering을 적용하지 않는 것보다 훨씬 결과가 좋은 것을 확인할 수 있다.
[Multi Crop evaluation]
multi crop과 dense evaluation을 각각 적용했을 때보다 같이 적용했을 때 성능이 개선된 것을 아래 표를 통해 알 수 있다.
[ ConvNet fusion]
앙상블에 대한 내용을 보면 모델 7개를 앙상블한 ILSVRC 제출물은 test set top-5 error가 7.5% 나왔고, 추후에 모델 2개를 앙상블하여 test set top-5 error를 6.8%까지 낮췄다고 한다.
▶ VGGNet 구현
간단하게 모델만 구축해보고자 한다!
# VGGNet은 4가지 종류 존재 >> 각 종류에 대한 정보를 딕셔너리를 만듦
# M : max pooling layer
# 숫자 : conv layer를 거친 후에 출력값 채널
VGG_types = {
'VGG11' : [64,'M',128,'M',256,256,'M',512,512,'M',512,512,'M'], # A
'VGG13' : [64,64,'M',128,128,'M',256,256,'M',512,512,'M',512,512,'M'], # B
'VGG16' : [64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M'], # C
'VGG19' : [64,64,'M',128,128,'M',256,256,256,256,'M',512,512,512,512,'M',512,512,512,512,'M'] # E
}
# define VGG16 model
class VGGnet(nn.Module):
def __init__(self, model, in_channels=3, num_classes=10, init_weights=True):
super(VGGnet, self).__init__()
self.in_channels = in_channels
# VGG type에 맞는 Conv layer 생성
self.conv_layers = self.create_conv_laters(VGG_types[model])
self.fc = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, num_classes)
)
# weight initialization
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.conv_layers(x)
x = x.view(-1,512*7*7)
x = self.fc(x)
return x
# weight initialization function
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# VGG type에 따른 conv layer를 만드는 function
def create_conv_laters(self, architecture):
layers = []
in_channels = self.in_channels # 3
for x in architecture:
if type(x) == int: # int는 conv layer를 의미
out_channels = x
layers += [nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=(3,3), stride=(1,1), padding=(1,1)),
nn.BatchNorm2d(x),
nn.ReLU()
]
elif x == 'M':
layers += [nn.MaxPool2d(kernel_size=(2,2), stride=(2,2))]
return nn.Sequential(*layers)
# device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# VGGNet object
model = VGGnet('VGG16', in_channels=3, num_classes=10, init_weights=True).to(device)
print(model)
AlexNet은 CNN의 가장 간단한 구조 중의 하나인 LeNet-5와 유사하다. 2개의 GPU를 이용해 병렬 연산을 수행했다는 것이 가장 큰 차이점이라고 볼 수 있다. AlexNet 덕분에 딥러닝, 특히 CNN이 주목을 받을 수 있었고, GPU 뿐만 아니라 dropout 적용이 보편화되었다.
▶ Data 전처리
1) 이미지 크기 256x256으로 고정
FC layer의 입력 크기는 고정되어 있기 때문에 별도의 전처리 과정이 필요하다. 입력 이미지의 크기가 다르면 FC layer에 입력되는 feature 개수가 모두 다르게 된다. 따라서 이미지의 크기를 256x256 크기로 고정을 시켜야 한다.
resize 방법으로 이미지의 넓이와 높이 중 더 짧은 쪽을 256으로 고정하고 중앙 부분을 256x256 크기로 crop 해준다.
2) 이미지의 RGB pixel 값에 변화를 줌
일반화 성능을 향상시키기 위해 조금 raw RGB pixel 들을 학습시켰다. 이를 수행하기 위해 학습 이미지 데이터들을 normalization 해주는 방법으로 각 이미지의 pixel에 training set의 평균을 뺐다.
[ 학습 이미지 - dataset 평균 = normalized 학습 이미지 ]
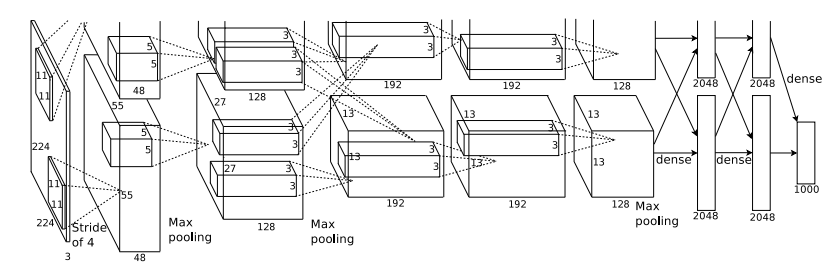
▶ AlexNet 구조
AlexNet은 Input - Conv1 - MaxPool1 - Norm1 - Conv2 - MaxPool2 - Norm2 - Conv3 - Conv4 - Conv5 - Maxpool3 - FC1- FC2 - Output 으로 구성되어 있으며 5개의 convolution layer와 3개의 fully connected layer를 이루어져 있다.
1) Input layer
AlexNet에 입력되는 것은 227x227x3 이미지이다. (그림에는 224로 잘 못 나옴)
2) 첫번째 Conv layer
[Conv1]
kernel size : 11x11x3, 96개
stride = 4, zero-padding = 0
input = 227x227x3
output = 55x55x96 [(227 - 11) / 4 + 1 = 55]
[MaxPool1]
3x3 kernels stride = 2
intput = 55x55x96
output = 27x27x96 [ (55 - 3) / 2 + 1 = 27 ]
[Norm1]
수렴 속도를 높이기 위해 LRN(Local Response Normalization) 사용한다.
6x6x256 feature map을 flatten 해서 9216 (6 * 6 * 256 )차원의 벡터로 만들어 4096개의 뉴런과 fully connected 해준다.
intput = 6x6x256
output = 4096
8) FC2 layer
intput = 4096
output = 4096
9) Output layer
1000개 뉴런의 출력값에 softmax 함수를 적용해 1000개 클래스 각각에 속할 확률을 나타낸다.
intput =4096
output = 1000
LeNet-5에서는 훈련시키는데 필요한 파라미터가 6만개 이었지만 AlexNet에서는 약 6천만개로 천배나 많아졌지만 그만큼 컴퓨팅 기술이 좋아졌고, 훈련시간을 줄이기 위한 방법들도 사용되었기 때문에 훈련이 가능하다.
▶ AlexNet의 특징
1) 활성화 함수로 ReLU를 적용
논문에 의하면 saturating nonlinearity (tanh, sigmoid) 보다 non-saturating nonlinearity (ReLU) 의 학습 속도가 빠르다고 한다. (점선 : tanh, 실선 : ReLU)
2) GPU parallelization
network를 2개의 GPU로 나누어서 학습시켰다. 2개의 GPU로 나누어서 학습시킨 결과 error가 감소되었으며 학습속도가 빨라졌다고 한다. 나눠서 학습을 시키다가 3번째 Conv layer에서만 GPU를 통합시켰는데 이를 통해 계산량의 허용가능한 부분까지 통신량을 정확하게 조정할 수 있다고 한다.
3) Overlapping Pooling
overlapping pooling은 pooling size가 stride size보다 작은 것을 의미한다. (pooling size < stride size)
이를 통해 overfitting을 방지하고 error를 낮출 수 있었다.
4) LRN (Local Response Normalization)
LRN은 generalize 하는 것이 목표이다. 여기서는 ReLU 함수를 사용하는데 양수 값을 받으면 그 값을 그대로 뉴런에 전달한다. 따라서 주변에 비해 어떤 뉴런이 비교적 강하게 활성화되어 있다면, 그 뉴런의 반응은 더욱 돋보이게 될 것이다. 강하게 활성화된 뉴런이 낮은 값의 뉴런이 전달되는 것을 방해할 수 있기 때문에 이를 예방하고자 normalization 하는 것이 LRN이라 할 수 있다.
5) Data Agumentation
overfitting을 방지하기 위해 현재 가지고 있는 데이터를 더 다양하게 만들어 CNN 모델을 학습시키는 것이다. 논문에서는 두가지 방법의 data agumentation을 적용했다.
- 이미지를 생성시키고 수평 반전을 해준다.
- 이미지의 RGB pixel 값에 변화를 준다
6) Dropout
AlexNet의 경우 학습하는데 시간이 오래 걸려서 앙상블 기법을 적용하는데 힘들었다고 한다. 따라서 모델 결합의 효과적인 dropout을 적용시켰다.
▶ AlexNet 구조
1. Import Library
import os
import torch
import torchvision
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.nn.functional as F
from PIL import Image
from torchvision import transforms, datasets
from torch.utils.data import Dataset, DataLoader
from google.colab import drive
drive.mount('/content/drive')
LeNet은 CNN을 처음 개발한 얀 르쿤(Yann Lecun) 연구팀이 1998년에 개발한 CNN 알고리즘의 이름이다.
손글씨를 기존에 있던 방법보다 더 나은 방식인 자동적인 방식으로 패턴을 인식할 수 있게 하기 위해 만들었다.
▶ LeNet-5 구조
LeNet-5 는 Input - Conv1 - Subsampling2 - Conv3 - Subsampling4 - Conv5 - FC6 - Output 으로 구성되어 있고, C1부터 F6까지 활성화 함수로 tanh을 사용한다.
1) C1 layer
Input으로 32x32 사이즈의 이미지를 6개의 5x5 필터와 컨볼루션 연산을 해서 6개의 28x28의 feature map을 얻는다.
[ parameter 수 : (weight * input map의 수 + bias) * feature map의 수 = (5 * 5 * 1 + 1) * 6 = 156 ]
2) S2 layer
6장의 28x28 feature map에 대해 subsampling을 진행한다. 여기서 사용하는 subsampling은 average poolig을 의미한다. 2x2 필터를 stride 2로 설정해 28x28 size를 14x14로 축소시켜준다.
원래 pooling은 parameter가 불필요한데 논문에 의하면 평균을 낸 후에 한개의 훈련가능한 weight를 곱해주고, 또 한개의 훈련 가능한 bias를 더해준다고 한다. 그 값이 sigmoid function을 통해 활성화된다. (+ 여기서 weight와 bias는 sigmoid의 비활성도를 조절해 준다.)
[parameter 수 : (weight + bias) * feature map의 수 = (1 + 1) * 6 = 12]
3) C3 layer ★★★★★
6장의 14x14 feature map에 컨볼루션 연산을 수행해서 16장의 10x10 feature map을 만들어 낸다.
[parameter 수 : (weight * input map의 수 + bias) * feature map의 수 = (5 * 5 * 16 + 1) * 120 = 48120]
6) F6 layer
C5의 결과를 84개의 유닛으로 input을 받는다.
[LeNet-5를 사용하기 위해 필요한 파라미터 수]
156 + 12 + 1516 + 32 + 48120 + 10164 = 60000개
▶ LeNet-5 의 특징
- 학습에 필요한 파라미터가 총 6만개(60K)로 너무 많다.
- 활성화 함수로 ReLU를 사용하지 않고, sigmoid or tanh를 사용했다.
- input 값인 이미지는 2D 구조로 인접한 픽셀들이 공간적으로 상관관계가 큰데 FC layer의 경우 픽셀을 단순히 배열하기 때문에 공간정보를 이용하지 못한다.
- pooling을 한 후에 비선형을 가지고 있지 않다.
- 제한된 특징만을 추출한다.
▶ LeNet-5 구현
1. Import Library
import numpy as np
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Accuracy function
def get_accuracy(model, data_loader, device):
# 전체 data_loader에 대한 예측의 정확도 계산
correct_pred = 0
n = 0
with torch.no_grad(): # inference 나 vaildation 할 때 gradient 계산 X (메모리 감소, 연산속도 증가)
model.eval() # 학습할 때 필요한 dropout, batch norm의 기능을 비활성화 시킴 (메모리 관련 X)
for X, y_true in data_loader:
X = X.to(device)
y_true = y_true.to(device)
_, y_prob = model(X)
_, predicted_labels = torch.max(y_prob, 1)
n += y_true.size(0)
correct_pred += (predicted_labels == y_true).sum()
return correct_pred.float() / n
# Loss function Visualize
def plot_loss(train_loss, valid_loss):
# training 과 validation loss를 시각화
plt.style.use('seaborn')
train_loss = np.array(train_loss)
valid_loss = np.array(valid_loss)
fig, ax = plt.subplots(figsize=(8, 4.5))
ax.plot(train_loss, color='blue', label='Training loss')
ax.plot(valid_loss, color='red', label='Validation loss')
ax.set(title='Loss over epochs',
xlabel='Epoch',
ylabel='Loss')
ax.legend()
fig.show()
plt.style.use('default')